
Bài này hoặc loạt bài này (nếu mình có thời gian) mình thực hiện bằng cách vừa học vừa viết lại, nguồn từ internet, chủ yếu mình lược dịch lại từ các trang web nước ngoài. Mục đích vừa để chia sẻ vừa để lại lưu trữ (sau này mình quên có thể vào để xem lại).
Xem thêm:
Hướng dẫn Nginx – Phần 1: Các khái niệm cơ bản
Tiếp tục phần 2:

tcp_nodelay, tcp_nopush, and sendfile
tcp_nodelay
Trong những ngày đầu của TCP, các kỹ sư phải đối mặt với nguy cơ sụp đổ do tắc ngẽn. Có một vài giải pháp nổi lên để ngăn chặn điều này, và một trong số đó là một thuật toán được John Nagle đề xuất.
Thuật toán của Nagle nhằm tránh bị tắt nghẽn bởi một số lượng lớn các gói nhỏ. Nó không can thiệp vào các gói TCP kích thước đầy đủ (Maximum Segment Size, hoặc MSS trong ngắn hạn), chỉ can thiệp vào các gói có kích thước nhỏ hơn MSS. Những gói đó sẽ được truyền chỉ khi người nhận gửi thành công tất cả các xác nhận của các gói trước đó (ACKs). Và trong thời gian chờ đợi, người gửi có thể lưu nhiều dữ liệu đệm hơn (buffer more data).
if package.size >= MSS.size
send(package)
elsif acks.all\_received?
send(package)
else
# accumulate data
end
Trong thời gian đó, một đề xuất khác xuất hiện: Delayed ACK.
Trong giao tiếp TCP, chúng ta gửi dữ liệu và nhận được các xác nhận (acknowledgements : ACKs) cho chúng tác biết rằng những dữ liệu đó đã được gửi thành công.
Delayed ACK cố gắng giải quyết vấn đề tắt ngẽn bởi một số lượng lớn các gói ACK. Để giảm thiểu nó, người nhận sẽ đợi một số dữ liệu sẽ được gửi tiếp để cộng chung các ACK với các dữ liệu đó. Nếu không có dữ liệu được gửi lại, chúng ta phải gửi các ACK ít nhất 2*MSS, hoặc từ 200 dến 500 ms (trong trường hợp chúng ta không còn nhận gói)
if packages.any?
send
elsif last_ack_send_more_than_2MSS_ago? || 200_ms_timer.finished?
send
else
# wait
end
Như bạn thấy điều này có thể dẫn đến một số tình trạng nan giải (deadlock) trong việc kết nối liên tục (emporary deadlocks on the persisted connection). Hãy ghi nhận nó.
Giả định:
- “Congestion window” (cửa sổ nghẽn) ban đầu bằng 2. Congestion window là một phần của cơ chế TCP khác gọi là Slow-Start. Các chi tiết khác không quan trong,bầy giờ chỉ cần ghi nhớ rằng nó hạn chế bao nhiêu gói có thể được gửi cùng một lúc. Trong round-trip (nôm na là trọn một vòng gửi và nhận dữ liệu) đầu tiên, chúng ta được phép gửi 2 gói MSS; trong round-trip thứ hai, 4 MSS; thứ ba, 8 MSS, v.v.
- 4 gói đệm chờ để được gửi: A, B, C, D.
- A, B, C là các gói MSS
- D là một gói nhỏ.
Kịch bản:
- Do “Congestion window” (cửa sổ nghẽn) ban đầu bằng 2, người gửi được phép gửi 2 gói: A và B.
- Người nhận gửi ACK khi nhận cả 2 gói.
- Người gửi truyền gói C. Tuy nhiên, Nagle chặn chúng ta gửi gói D (gói quá nhỏ, vì vậy chúng ta cần phải chờ ACK từ C)
- Về phía người nhận, ”Delayed ACK” ngăn cản anh ta gửi ACK (được gửi mỗi 2 gói hoặc mỗi 200 ms)
- Sau 200ms, người nhận gửi ACK cho gói C.
- Người gửi nhận ACK và gửi gói D.
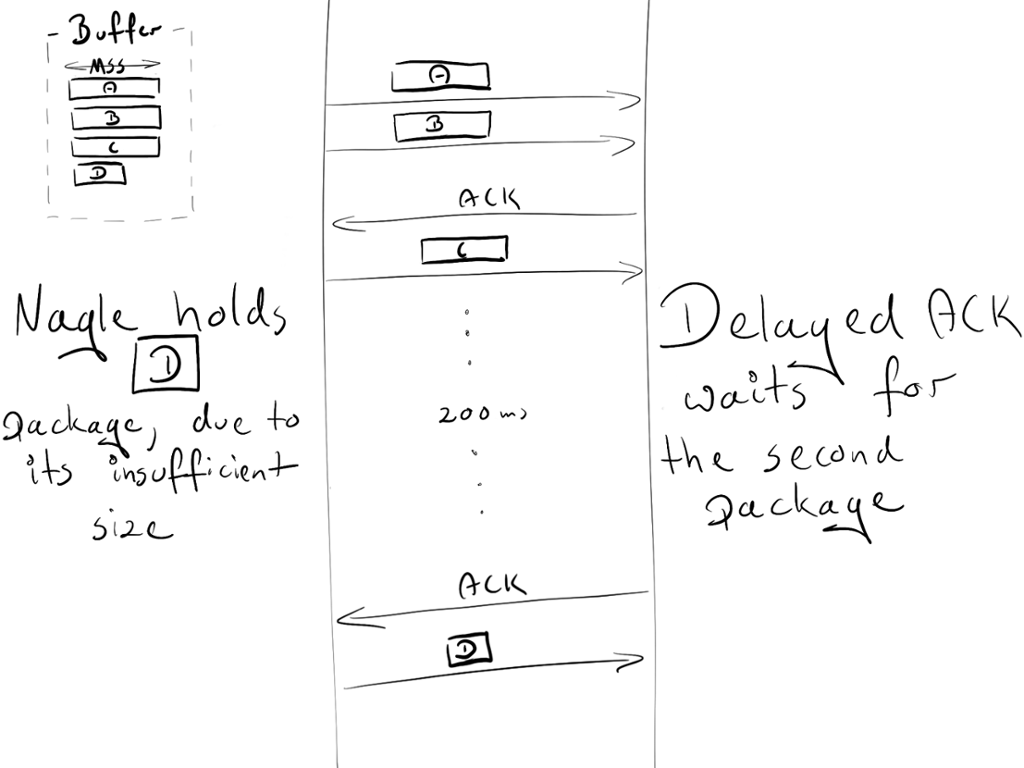
Trong suốt quá trình trao đổi này, có một độ trễ là 200ms do sự bế tắc (deadlock) giữa Nagle và Delayed ACK.
Thuật toán Nagle là một vị cứu tinh thực sự trong thời đại của mà nó xuất hiện và nó vẫn mang lại giá trị lớn thời điểm hiện tại. Tuy nhiên, trong hầu hết các trường hợp, chúng ta sẽ không cần nó cho trang web của chúng ta và mà vẫn giải quyết được vấn đề bằng cách thêm tcp_nodelay.
tcp_nodelay on; # Bật TCP_NODELAY , sử dụng trên những kết nối keepalive
Ok, hãy tận hưởng lợi ích từ 200ms.
Nếu bạn giỏi tiếng anh và muốn tìm hiều thêm về phần này thì tải file này về xem: Rethinking the TCP Nagle Algorithm
sendfile
Thông thường, khi một file cần được gửi, bắt buộc phải có các bước sau đây:
malloc(3): Cấp phát bộ đệm cục bộ (local buffer) để lưu trữ dữ liệu đối tượng (object data)read(2): Lấy và sao chép đối tượng vào bộ đệm cục bộ (local buffer) đã được cấp phát.write(2): Sao chép đối tượng từ bộ đệm cục (local buffer) bộ vào bộ đệm ổ cắm (socket buffer)
Điều này liên quan đến 2 context switches (read, write) tạo ra một bản sao thứ hai của cùng một đối tượng không cần thiết. Như bạn thấy, nó không phải là cách tối ưu. May mắn là, có một cách gọi hệ thông khác giúp cải thiện việc gửi file, và nó được gọi là: sendfile(2) . Nó lấy một đối tượng vào file cache, và ”passes pointers” (mà không cần sao chép toàn bộ đối tượng) thẳng đến “socket descriptor”. Netflix nói rằng việc sử dụng sendfile (2) làm tăng thông lượng mạng từ 6Gbps lên 30Gbps
Tuy nhiên có một số sendfile(2) nhược điểm:
- không hoạt động mới UNIX sockets (Vd: khi phân phối file tĩnh thông qua máy chủ upstream)
- hiệu suất có thể khác nhau tùy thuộc vào hệ điều hành (xem thêm ở đây)
Để bật thứ hay ho này trong nginx, gõ:
sendfile on;
tcp_nopush
tcp_nopush là đối nghịch với tcp_nodelay. Thay vì đẩy các gói càng nhanh càng tốt, nó nhằm tối ưu hóa lượng dữ liệu được gửi đồng thời.
Nó buộc các gói phải chờ đợi đến khi đạt kích thước tối đa (MSS) trước khi gửi đến cho máy khách. Directive này chỉ hoạt động khi sendfile được bật
sendfile on;
tcp\_nopush on;
Như bạn thấy, có vẻ như tcp_nopush và tcp_nodelay loại trừ lẫn nhau. Nhưng nếu cả 3 directive đều được bật, nginx sẽ:
- đảm bảo các gói đã đầy đủ kích thước trước khi gửi chúng cho máy khách.
- đối với gói cuối cùng,
tcp_nopushsẽ bị xóa, cho phép TCP gửi nó ngay lập tức mà không bị delay 200ms
Nên có bao nhiêu process?
Worker processes
worker_process directive định nghĩa số lượng worker sẽ được chạy. Theo mặc định, giá trị này được đặt thành 1. Đơn giản và an toàn nhất là sử dụng số lõi (core) của hệ thống bằng cách đặt auto
Tuy nhiên, do kiến trúc của Nginx xử lý yêu cầu rất nhanh chóng, chúng ta có thể sẽ không sử dụng đến 2-4 quy trình (processes) cùng một lúc (trừ khi bạn làm những web như facebook hoặc thực hiện một số nội dung chuyên sâu về CPU bên trong nginx)
worker_process auto;
Worker connections
directive liên quan trực tiếp đến worker_process là worker_connections. Nó chỉ định có bao nhiêu kết nối có thể được mở bởi worker process cùng một lúc. Số này thể hiện tất cả các kết nối không phải chỉ là kết nối với máy khách (vd: kết nối với máy chủ proxy). Ngoài ra, cần lưu ý rằng một máy khách có thể mở nhiều kết nối để tìm nạp các tài nguyên khác cùng một lúc.
worker_connections 1024;
Open files limit
“Mọi thứ đều là một file” trong các hệ thống dựa trên Unix. Nó có nghĩa là các tài liệu, thư mục, pipes, hoặc thậm chí là các sockets. Hệ thống có một giới hạn bao nhiêu tập tin có thể được mở đồng thời bởi một quá trình (process). Để kiểm tra giới hạn gõ:
ulimit -Sn # soft limit
ulimit -Hn # hard limit
Giới hạn hệ thống này phải được tinh chỉnh theo worker_connections. Mọi kết nối đến sẽ mở ít nhất một tệp (thường là hai kết nối socket và kết nối phụ trợ khác hoặc file tĩnh trên ỗ đĩa). Vì vậy, tốt nhất là để giá trị này bằng với worker_connections X 2. May mắn thay, Nginx cung cấp tùy chọn tăng giá trị hệ thống này trong cấu hình nginx. Để cấu hình, hãy thêm directive worker_rlimit_nofile với giá trị thích hợp và reload lại nginx.
worker_rlimit_nofile 2048;
Config
Nói dài dòng để hiểu hơn thôi, cuối cùng chúng ta cấu hình lại đơn giản như sau:
worker_process auto;
worker_rlimit_nofile 2048; # Changes the limit on the maximum number of open files (RLIMIT_NOFILE) for worker processes.
worker_connections 1024; # Sets the maximum number of simultaneous connections that can be opened by a worker process.
Số lượng kết nối tối đa:
Với các tham số ở trên, chúng ta có thể tính toán số lượng kết nối mà chúng ta có thể xử lý đồng thời:
max no of connections =
worker_processes * worker_connections
----------------------------------------------
(keep_alive_timeout + avg_response_time) * 2
keep_alive_timeout (sẽ nói thêm sau) + avg_response_time cho chúng ta biết thời gian kết nối được mở. Chúng ta chia nó cho 2, vì bạn thường sẽ có 2 kết nối được mở bởi một máy khách: một giữa nginx và máy khách, một giữa nginx và upstream serve
Gzip
Bật gzip sẽ làm giảm đáng kể trọng lượng phản hồi của bạn, do đó nó sẽ xuất hiện nhanh hơn ở phía máy khách
Compression level
Gzip có mức độ nén (compression level) khác nhau: từ 1 đến 9. Tăng mức này sẽ giảm kích thước của tệp, nhưng cũng tăng mức tiêu thụ tài nguyên. Tốt nhất nên giữu số này từ 3 đến 5, bởi vì việc tăng mức độ này sẽ mang lại lợi ích rất nhỏ nhưng làm tăng đán kế mức sử dụng CPU.
Dưới đây là ví dụ về việc nén tệp bằng gzip với các cấp độ khác nhau. 0 là viết tắt của một tập tin không nén.
curl -I -H 'Accept-Encoding: gzip,deflate' <https://sofsog.com/>
❯ du -sh ./\*
64K ./0\_gzip
16K ./1\_gzip
12K ./2\_gzip
12K ./3\_gzip
12K ./4\_gzip
12K ./5\_gzip
12K ./6\_gzip
12K ./7\_gzip
12K ./8\_gzip
12K ./9\_gzip
❯ ls -al
-rw-r--r-- 1 matDobek staff 61711 3 Nov 08:46 0\_gzip
-rw-r--r-- 1 matDobek staff 12331 3 Nov 08:48 1\_gzip
-rw-r--r-- 1 matDobek staff 12123 3 Nov 08:48 2\_gzip
-rw-r--r-- 1 matDobek staff 12003 3 Nov 08:48 3\_gzip
-rw-r--r-- 1 matDobek staff 11264 3 Nov 08:49 4\_gzip
-rw-r--r-- 1 matDobek staff 11111 3 Nov 08:50 5\_gzip
-rw-r--r-- 1 matDobek staff 11097 3 Nov 08:50 6\_gzip
-rw-r--r-- 1 matDobek staff 11080 3 Nov 08:50 7\_gzip
-rw-r--r-- 1 matDobek staff 11071 3 Nov 08:51 8\_gzip
-rw-r--r-- 1 matDobek staff 11005 3 Nov 08:51 9\_gzip
gzip_http_version 1.1;
directive này nói cho nginx sử dụng gzip chỉ đối với HTTP 1.1 trở lên. Chúng tôi không bao gồm HTTP 1.0 ở đây, bởi vì đối với phiên bản 1.0, bạn không thể sử dụng cả keepalive và gzip. Bạn phải quyết định chọn một thứ bạn thích: các máy khách HTTP 1.0 không có các ứng dụng khách gzip hoặc HTTP 1.0 không có keepalive.
Config
gzip on; # bật gzip
gzip_http_version 1.1; # chỉ bật gzip cho http 1.1 và cao hơn
gzip_disable "msie6"; # IE 6 gặp sự cố với gzip
gzip_comp_level 5; # inc compresion level và mức sử dung CPU
gzip_min_length 100; # trọng lượng tối thiếu cho tiệp gzip
gzip_proxied any; # Bật gzip cho proxied requests (vd: CDN)
gzip_buffers 16 8k; # bộ đệm nén (nếu chúng ta vượt quá giá trị này, đĩa cứng sẽ được sử dụng thay cho RAM)
gzip_vary on; # add header Vary Accept-Encoding (sẽ nói thêm bên dưới phần Cache)
# Xác định file cần được nén
gzip_types text/plain;
gzip_types text/css;
gzip_types application/javascript;
gzip_types application/json;
gzip_types application/vnd.ms-fontobject;
gzip_types application/x-font-ttf;
gzip_types font/opentype;
gzip_types image/svg+xml;
gzip_types image/x-icon;
Caching
Caching là một thứ khác có thể tăng tốc yêu cầu (requests) một cách độc đáo cho người dùng cũ. Quản lý bộ nhớ cache có thể được kiểm soát chỉ bằng hai tiêu đề (header):
Cache-Controlđể quản lý cache trong HTTP/1.1Pragmađể tương thích ngược với các máy khách HTTP / 1.0
Cache có thể được chia thành hai loại: bộ nhớ cache công khai (public cache) và riêng tư (private cache). Public Cache lưu trữ những phản hồi (responses) để sử dụng lại cho nhiều người dùng. Private cache được dành riêng cho một người dùng.
add_header Cache-Control public;
add_header Pragma public;
Đối với nội dung tiêu chuẩn, chúng ta nên giữ chúng trong thời gian 1 tháng:
location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ {
expires 1M;
add_header Cache-Control public;
add_header Pragma public;
}
Cấu hình như bên trên cơ bản đã đủ. Tuy nhiên, nó có một thông báo trước khi sử sụng public cache.
Hãy xem điều gì sẽ xảy ra nếu chúng ta lưu trữ nội dung của mình trong bộ nhớ cache công khai (ví dụ: CDN) với URI làm số nhận dạng (identifier) duy nhất. Trong trường hợp này, chúng ta cũng giả định rằng gzip đang bật.
Chúng ta có 2 trình duyệt:
- một cái dúng phiên bản cũ, không hỗ trợ gzip
- một cái trình duyệt mới có hỗ trợ gzip
Trình duyệt phiên bản cũ gửi yêu cầu sofsog.com/style.css đến CDN của chúng ta. Vì CDN chưa có tài nguyên này, nó sẽ truy vấn máy chủ của chúng ta và trả về phản hồi (response) không nén. CDN lưu trữ tập tin đã được băm (hash) (để sử dụng sau này):
{
...
sofsog.com/styles.css => FILE("/sites/sofsog/style.css")
...
}
Cuối cùng, file sẽ được trả lại cho máy khách.
Bây giờ, trình duyệt mới gửi cùng một yêu cầu tới CDN, yêu cầu sofsog.com/style.css, mong đợi một tài nguyên gzipped. Vì CDN chỉ xác định tài nguyên bởi URI, nó sẽ trả về cùng một tài nguyên không nén cho trình duyệt mới. Trình duyệt mới sẽ cố gắng trích xuất một tệp không được nén và sẽ nhận được rác.
Nếu chúng ta có thể yêu cầu bộ nhớ cache công khai xác định tài nguyên dựa trên URI và mã hóa, chúng tôi có thể tránh vấn đề này.
{
...
(sofsog.com/styles.css, gzip) => FILE("/sites/sofsog/style.css.gzip")
(sofsog.como/styles.css, text/css) => FILE("/sites/sofsog/style.css")
...
}
Và đây chính xác là những gì Vary Accept-Encoding; làm. Nó cho bộ nhớ ”public cache” biết rằng một tài nguyên có thể được phân biệt bởi một URI và một tiêu đề Accept-Encoding.
Vì vậy, cấu hình cuối cùng của chúng ta sẽ như sau:
location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ {
expires 1M;
add_header Cache-Control public;
add_header Pragma public;
add_header Vary Accept-Encoding;
}
Timeouts
Client_body_timeout và client_header_timeout xác định thời gian bao lâu nginx sẽ đợi cho một khách hàng truyền tải nội dung (body) hoặc tiêu đề (header) trước khi báo lỗi 408 (Yêu cầu hết thời gian: Request Time-out).
send_timeout đặt thời gian chờ để truyền phản hồi cho khách hàng. Thời gian chờ được đặt chỉ giữa hai thao tác ghi liên tiếp, không phải cho việc truyền toàn bộ phản hồi. Nếu khách hàng không nhận được bất cứ điều gì trong thời gian này, kết nối được đóng lại.
Hãy cẩn thận khi thiết lập các giá trị bên trên, vì thời gian chờ đợi quá lâu có thể làm bạn dễ bị tấn công, trong khi thời gian quá ngắn không đủ để phản hồi các máy khách chậm.
# Configure timeouts
client_body_timeout 12;
client_header_timeout 12;
send_timeout 10;
Buffers
client_body_buffer_size
Đặt kích thước bộ đệm (buffer) để đọc phần thân yêu cầu của máy khách (client’s request body). Trong trường hợp phần thân yêu cầu lớn hơn vùng đệm, toàn bộ phần thân hoặc chỉ một phần của nó được ghi vào một tệp tạm thời. Đối với client_body_buffer_size, thiết lập 16k là đủ trong hầu hết các trường hợp.
Đây là lại là một thiệt lập có thể gây tác động lớn, nhưng nó phải được sử dụng cẩn thận. Đặt quá ít, và nginx sẽ liên tục sử dụng I / O để viết các phần còn lại vào tệp. Đặt quá nhiều, và bạn sẽ làm cho mình dễ bị tấn công DOS khi kẻ tấn công có thể mở tất cả các kết nối, nhưng bạn không thể phân bổ bộ đệm trên hệ thống của bạn để xử lý các kết nối đó.
client_header_buffer_size và large_client_header_buffers
Nếu tiêu đề (header) không vừa với client_header_buffer_size thì big_client_header_buffers sẽ được sử dụng. Nếu yêu cầu vẫn không phù hợp với bộ đệm đó, lỗi sẽ được trả lại cho khách hàng. Đối với hầu hết các yêu cầu, một bộ đệm 1K byte là đủ. Tuy nhiên, nếu một yêu cầu bao gồm cookie dài (long cookies), 1K byte có thể không phù hợp.
Nếu kích thước của một dòng yêu cầu (request line) bị vượt quá, lỗi 414 (Yêu cầu-URI quá lớn) được trả lại cho máy khách.
Nếu kích thước của request header bị vượt quá, lỗi 400 (Yêu cầu Không hợp lệ) sẽ được thông báo.
client_max_body_size
Đặt kích thước tối đa cho phép của thân yêu cầu khách hàng (client request body), được chỉ định trong trường “Content-Length” request header. Tùy thuộc vào việc bạn có muốn cho phép người dùng tải tệp lên hay không, hãy tinh chỉnh cấu hình này theo nhu cầu của bạn.
Config
client\_body\_buffer\_size 16K;
client\_header\_buffer\_size 1k;
large\_client\_header\_buffers 2 1k;
client\_max\_body\_size 8m;
Keep-Alive
Giao thức TCP, dựa trên HTTP, yêu cầu thực hiện một ”three-way handshake” để bắt đầu kết nối. Điều đó có nghĩa là trước khi máy chủ có thể gửi dữ liệu cho bạn (ví dụ: hình ảnh), cần thực hiện ba vòng tròn đầy đủ giữa máy khách và máy chủ.
Giả sử bạn đang yêu cầu /image.jpg từ Warsaw và kết nối với máy chủ gần nhất ở Berlin:
Open connection
TCP Handshake:
Warsaw ->------------------ synchronise packet (SYN) ----------------->- Berlin
Warsaw -<--------- synchronise-acknowledgement packet (SYN-ACK) ------<- Berlin
Warsaw ->------------------- acknowledgement (ACK) ------------------->- Berlin
Data transfer:
Warsaw ->---------------------- /image.jpg --------------------------->- Berlin
Warsaw -<--------------------- (image data) --------------------------<- Berlin
Close connection
Đối với yêu cầu khác, bạn sẽ phải thực hiện lại toàn bộ quá trình khởi tạo này một lần nữa. Nếu bạn gửi nhiều yêu cầu trong một khoảng thời gian ngắn, điều này có thể tăng tốc dộ. Và đây là nơi mà keepalive có ích. Sau khi phản hồi thành công (successful response), nó giữ kết nối nhàn rỗi (connection idle) trong một khoảng thời gian nhất định (ví dụ 10 giây). Nếu yêu cầu khác được thực hiện trong thời gian này, kết nối hiện tại sẽ được sử dụng lại và thời gian nhàn rỗi (idle time) được làm mới.
Nginx cung cấp một vài chỉ thị (directives) mà bạn có thể sử dụng để chỉnh sửa cài đặt keepalive. Chúng có thể được nhóm thành hai loại:
- keepalive giữa khách hàng và nginx
keepalive_disable msie6; # tắt keepalive trên IE6
# Số lượng yêu cầu mà khách hàng có thể thực hiện qua một kết nối duy nhất
# Giá trị mặc định là 100, nhưng giá trị cao hơn nhiều có thể đặc biệt hữu ích
# khi thử nghiệm với load‑generation tool, thường gửi một số lượng lớn các yêu cầu từ một máy khách đơn
keepalive_requests 100000;
# Thời gian idle keepalive connection mở
keepalive_timeout 60;
- keepalive giữa khách hàng và upstream
upstream backend {
# Số lượng các kết nối "idle keepalive" đến "upstream server" được mở cho mỗi worker process
keepalive 16;
}
server {
location /http/ {
proxy_pass <http://http_backend>;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
OK, được 1 phần nữa
Kết luận
Cảm ơn các bạn đã đọc đến đây. Loạt bài này sẽ không thể có được nếu không có số lượng lớn tài nguyên được tìm thấy trên internet. Dưới đây là một số trang web tuyệt vời mà mình thấy đặc biệt hữu ích khi viết loạt bài này:
- nginx docs
- nginx blog
- nginx fundamentals on udemy
- Ilya Grigorik blog, và cuốn sánh của anh ta: High Performance Browser Networking
- Martin Fjordvald blog
Mình sẽ rất vui khi thấy một số phản hồi hoặc thảo luận, vì vậy, vui lòng để lại nhận xét hoặc liên lạc lại bằng bất kỳ cách nào thuận tiện! Bạn có thích hướng dẫn này không? Bạn có gợi ý gì về chủ để tiếp theo không? Hoặc có thể bạn phát hiện ra một số lỗi? Hãy cho mình biết nhé và hẹn gặp lại bạn lần sau!
Xem tiếp phần 3:
Hướng dẫn Nginx – Phần 3: Cài đặt SSL
Lược dịch từ: netguru.co




Để lại bình luận
Email của bạn sẽ được giữ bí mật. Các phần bắt buộc được đánh dấu *